
Having seen quite a bit of buzz about Claude 3, I decided to try a side-by-side comparison vs. GPT 4 for Morfi, the AI service I’m building for ecommerce sites.
For the past few months, GPT 4 was the only model that was viable for this early product. Here’s a quick sample of what Morfi is doing:
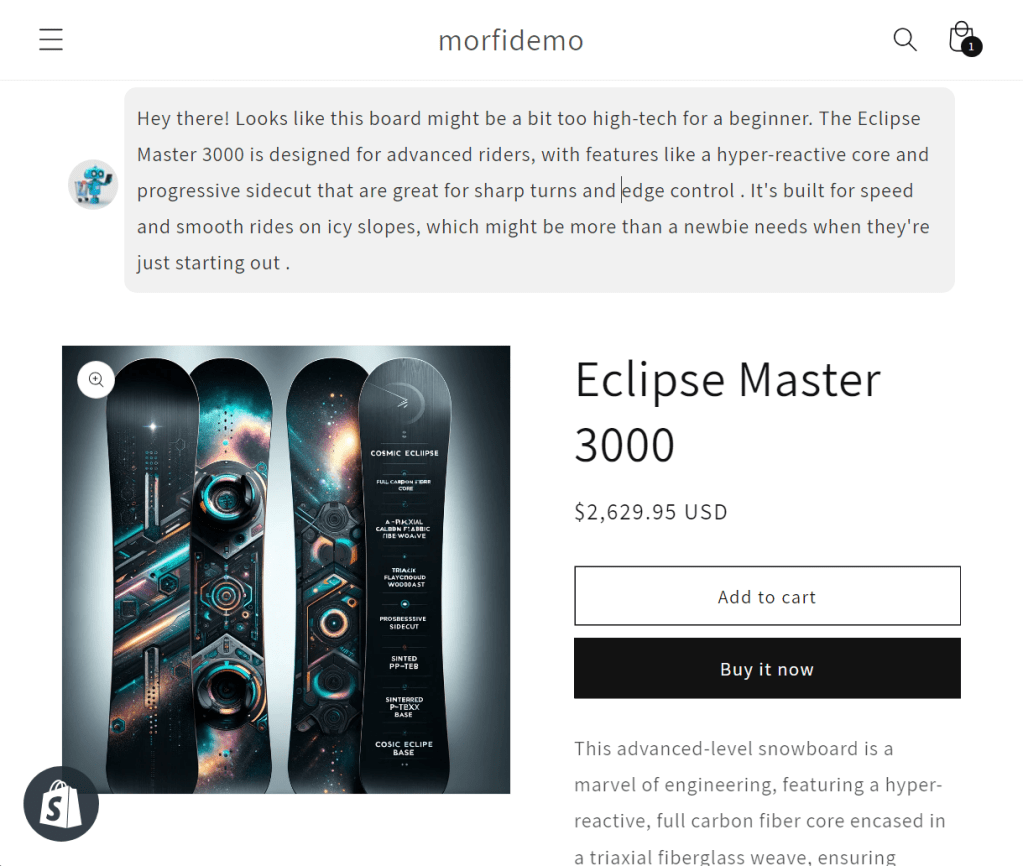
To set the stage, the user has just searched for “beginner snowboard”, and then has navigated to this page while shopping. Morfi has been asked to add additional commentary to the base product content, to highlight why this product might be a good fit — or, why not! To date, the other models I’d tried had failed this test, sometimes giving answers that tried to ‘spin’ this board as good for a beginner when it’s clearly an advanced board. GPT 3.5, Groq, Gemini all sometimes fell for this.
Let’s see how Claude 3 does:
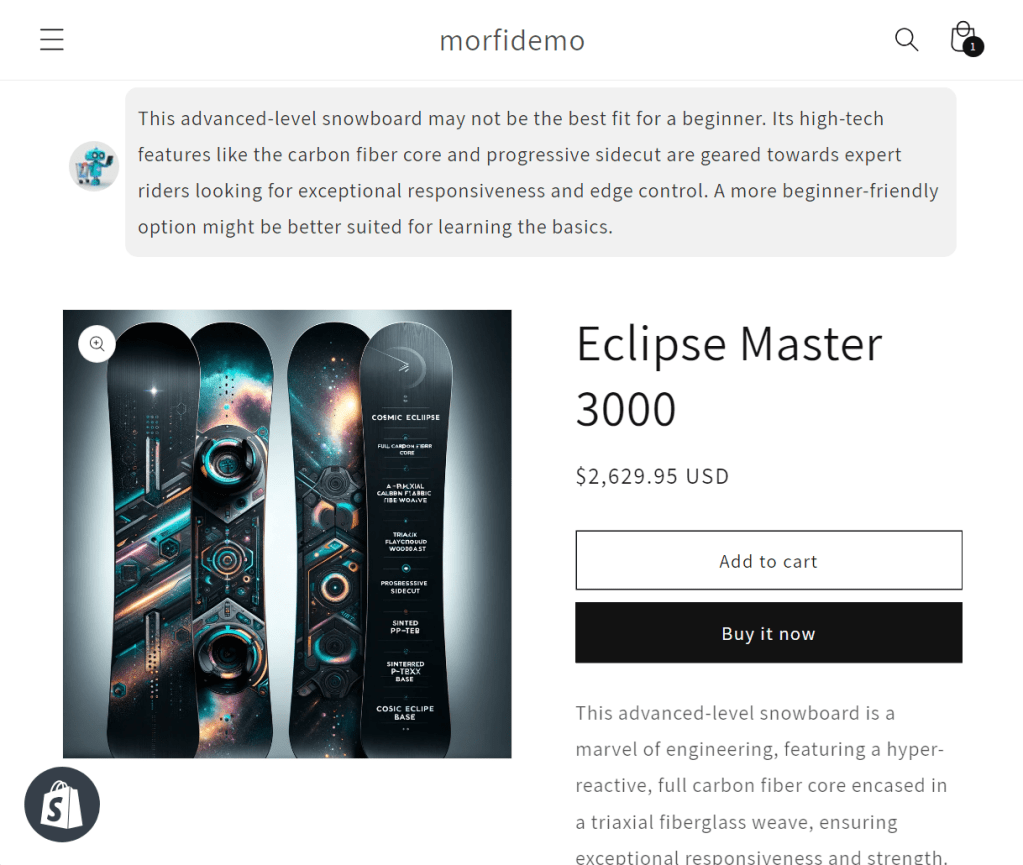
Hey, not bad! We can quibble about tone, but it’s not acting like a sleazy salesman and trying to spin the board as something it’s not. This was coming from their Opus model as well, which is notably a bit faster and cheaper than the GPT 4 model I was using. I ran it through a battery of scenarios, and it matched GPT 4 for *honesty* of answers based on the underlying product data.
It’s not a slam-dunk win — there’s a question of tone and creativity, so I’ll need a lot more data to evaluate which model does a better job increasing conversion rate. But the important thing: the early testing is telling me that it’s no longer a one-horse race, at least for my use case. I’ve been waiting for OpenAI to get some real competition, and it feels like it has landed. Let the games begin!

Leave a reply to lkrulik Cancel reply